An attempt to answer one question which all people trying to pick a front end framework has . Is Angular or React the right choice ? Angular vs React is a burning adoption question on most Project planning sessions and one which often a developer has to confront. React is a Facebook supported initiative and is a javascript library . It would be wrong to call it a framework based on its initial release versions . It helps to create resusable components in applications and is javascript based . Angular has equally competent heritage from Google .With Angular being a new version to previous Angular JS which was widely successful. Angular has now ditched Javascript and adopted Typescript , i was very skeptic of this choice especially typescript being previously unknown in the front end developer circles . Once I started using Typescript I could see some clear advantages and choice for strong typing which was missing in Javascript for long was being enforced. Of...
Lambda is a most discussed architecture pattern in data science space .The below is an attempt to explain it .
Lambda is a data processing architecture and framework
designed to address robustness and scalability and fault tolerance of big data
systems.
In this study we are planning to focus on the batch and
speed layers to achieve data processing.
As proposed in the summary for both the batch and stream we
will be using Spark.
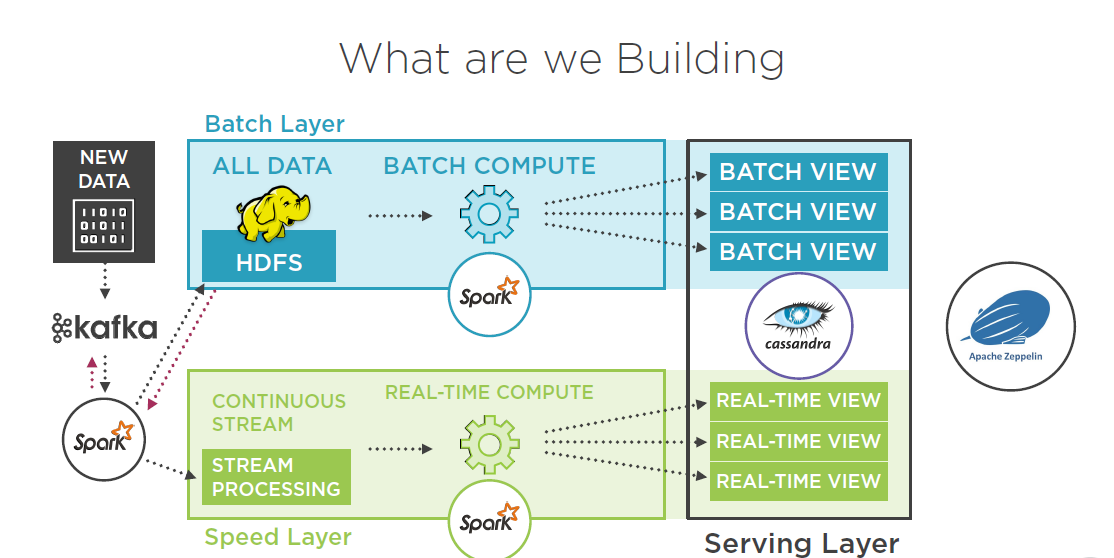
What constitutes the lambda architecture for data
processing?
Lambda is a architecture pattern .
Here the architecture we investigate has Lambda implemented
primarily with Spark for batch and stream processing, Cassandra for No -SQL
database storage, Kafka for accessing and sending
the stream data and Zeppelin for visualizations.
Sample application workflow investigated -
In this sample application Spark is used for both batch and real time.
We will persist the data in HDFS to perform batch operations against it.
[HDFS stands for Hadoop distributed file system]
We will persist the data in HDFS to perform batch operations against it.
[HDFS stands for Hadoop distributed file system]
We can use the same processing framework, We can also reuse
code leveraging business logic and our experience from the implementation
of another layer.
In this case we have investigated storing the data in
Cassandra, and we'll be using Zeppelin to visualize some of our data and
run some Spark and Cassandra commands.
The application used click stream producer to send data to
Kafka in a few different formats .
The sample application we are going to create uses Spark to synchronise the data to HDFS and perform the stream and batch processing.
The sample application we are going to create uses Spark to synchronise the data to HDFS and perform the stream and batch processing.
What is Apache Spark?
Spark is a general-purpose cluster computing platform designed
with components for scheduling and executing against large datasets.
Spark is now in version 2.X where there is more focus on structured
streaming.
How spark fits into lambda Architecture?
Spark is a general engine for large -scale data processing.
It also scales horizontally like Map Reduce the major difference comes in the speed.
It also scales horizontally like Map Reduce the major difference comes in the speed.
Spark is one of those frameworks that was built to address
some of the inefficiencies with MapReduce.
Spark performs specific optimizations by building its own directed acyclic graph or DAG based on your program and optimizes that DAG with a substantially less amount of data hitting disk and passed on through memory instead.
Spark also builds its own execution DAG as well and has its own optimizations and scheduling for executing that DAG.
Spark performs specific optimizations by building its own directed acyclic graph or DAG based on your program and optimizes that DAG with a substantially less amount of data hitting disk and passed on through memory instead.
Spark also builds its own execution DAG as well and has its own optimizations and scheduling for executing that DAG.
The core strength of
Spark's performance when compared to other frameworks is that it can
utilize memory and cache objects efficiently and that it also keeps a lineage graph of your operations, so it can re-compute on failures.
These are two of the fundamental things that the resilient distributed dataset implementation in Spark is all about.
These are two of the fundamental things that the resilient distributed dataset implementation in Spark is all about.
What are the Spark components and how to perform scheduling?
Spark downloaded usually contains the Spark Core that includes high-level API and an optimised engine
that supports general execution graphs, Spark SQL for SQL and structured data processing, and Spark Streaming that enables scalable, high-throughput, fault-tolerant
stream processing of live data streams. Spark MLLIb contains the machine learning
libraries.
GraphX is for graph computations.
GraphX is for graph computations.
Spark also supports a variety of languages like Java, Python,
Scala, and R.
Different Aggregations available in Spark
RDD API
Fundamental abstraction and building block. RDD represents a
“Resilient Distributed Dataset”.
RDD which is a collection of elements partitioned across the
nodes of the cluster that can be operated on in parallel. RDDs are created by
starting with a file in the Hadoop file system (or any other Hadoop-supported
file system), or an existing Scala collection in the driver program, and
transforming it. Users may also ask Spark to persist an RDD in
memory, allowing it to be reused efficiently across parallel operations.
Finally, RDDs automatically recover from node failures.
Data Frame and Dataset API’s
Like an RDD, a Data Frame is an immutable distributed collection of data. Unlike
an RDD, data is organized into named columns, like a table in a relational
database. Designed to make large data sets processing even easier, Data Frame
allows developers to impose a structure onto a distributed collection of data,
allowing higher-level abstraction; it provides a domain specific language API
to manipulate your distributed data; and makes Spark accessible to a wider
audience, beyond specialized data engineers.
Spark 1.6 brings us a Dataset API, which adds to the Data
Frame API by adding type safety to the structured table
representation of data that Data Frames bring.
Caching
Spark also supports pulling data sets into a cluster-wide
in-memory cache. This is very useful when data is accessed repeatedly, such as
when querying a small “hot” dataset or when running an iterative algorithm like
PageRank.
Comments
Post a Comment